Technologie
High-Tech Herzstück
Das Dokumenten-KI-System kinisto ermöglicht die ganzheitliche Prozessoptimierung dokumentenbasierter Prozesse. Herz des Systems ist unsere “Contextual AI”. Sie ermöglicht das Erkennen von Informationen im Kontext. So lassen sich selbst lange, komplexe Texte oder tabellarisch aufgebaute Dokumente analysieren und die Daten strukturiert auslesen.
Natural Language Processing
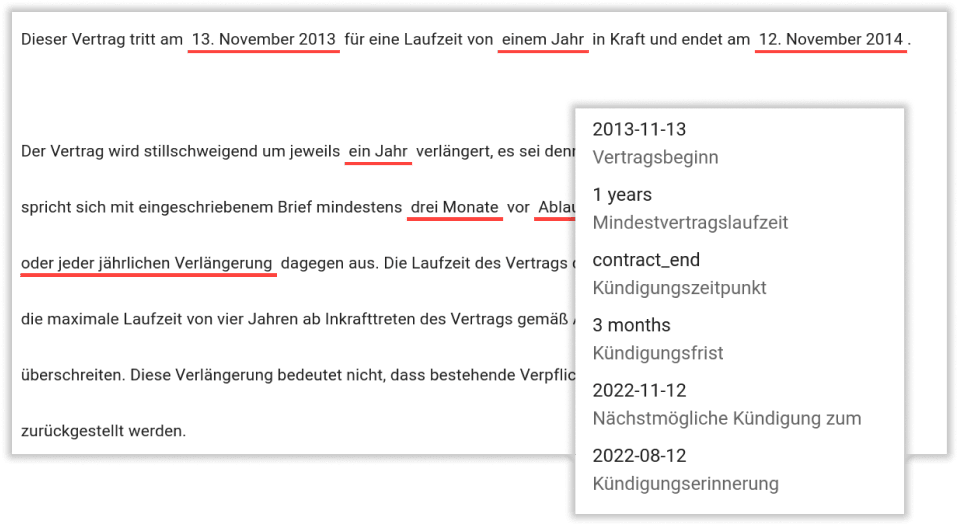
Contextual AI
kinisto erkennt die Beziehung von Textelementen zueinander und liest so Informationen aus jeder Art von Text, unabhängig von Aufbau und Format, aus. Dabei ist kinisto schnell, hochperformant, effizient und vor allem präzise.
Natürliche Sprache wird zunächst in einzelne Bestandteile geclustert und die Bedeutung der Textelemente sowie deren Position erfasst. Im Anschluss setzt kinisto wiederum alle erfassten Textelemente in Kontext zueinander – sowohl sprachlich als auch bezogen auf die Position im Dokument. Es lassen sich also auch komplexe inhaltliche Zusammenhänge in unterschiedlichsten Layouts, Formaten und Formulierungen erfassen.
kinisto liest Texte und Dokumente wie ein Mensch – nur schneller und präziser.

High-performance Modelltraining
Data-Centric Active Learning
Effizient zum kinisto Daten-Extraktions-Modell: Mit kinisto Studio, unserer eigenen State-of-the-Art NLP-Entwicklungsumgebung für Data Scientists, trainieren wir hochperformante Modelle für die kontextuelle Text- und Dokumentenanalyse. Die innovative Active Learning Technologie von kinisto Studio, kombiniert mit der Möglichkeit, in kurzen Iterationszyklen Rohdaten, Annotation und Modell zu optimieren, ermöglicht das Training in Rekordzeit.
Trainingsdaten sind der größte Hebel für Performance. Unsere Data-Centric Active Learning Technologie optimiert Trainingsdaten für kinisto. Die besten Trainingsdaten wählt kinisto selbst und generiert zudem auf Basis existierender Beispiele neue Trainingsdaten für maximale Varianz. In der integrierten Entwicklungsumgebung für Data Scientists werden in kurzen Iterationszyklen Rohdaten, Annotation und Modell optimiert.
Dadurch verringert sich die Trainingszeit für neue Anwendungsfälle um bis zu 80% und es werden bis zu 98% weniger Trainingsdaten benötigt. kinisto kann dadurch außerdem selbst für Anwendungsfälle mit sensiblen Daten trainiert werden, bei denen keine echten Trainingsdaten verfügbar sind.
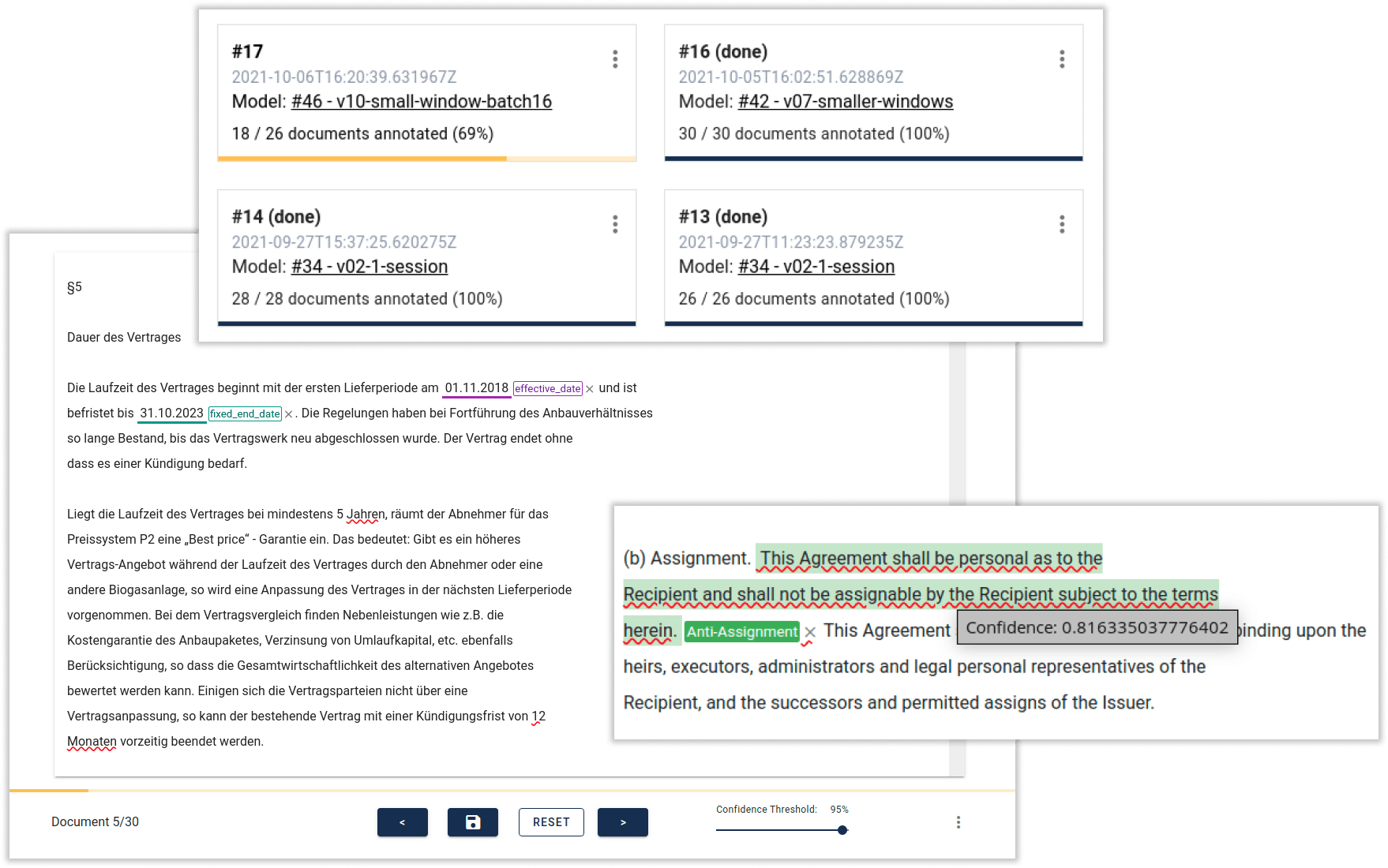
Das bedeutet für Ihren speziellen Anwendungsfall: kinisto ist in kürzester Zeit einsatzbereit - vom ersten Proof of Concept bis zum Einsatz der fertigen Lösung. Effizienter, performanter, präziser: Automatisieren Sie Ihre dokumentenbasierten Prozesse jetzt mit innovativer KI Technologie.
