Technology
High-tech centerpiece
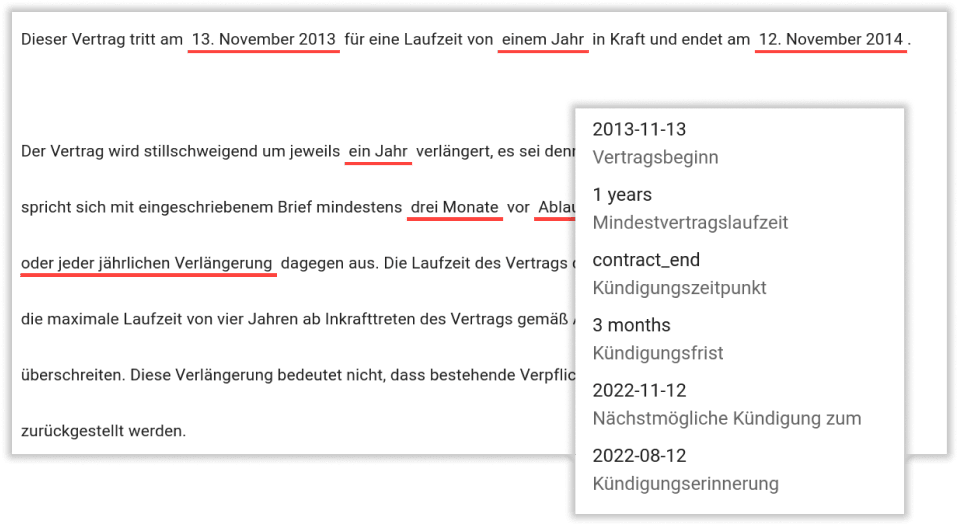
The document AI system kinisto recognizes information in context. Our “Contextual AI” processes information even in long, complex texts or tabular documents on a human level - and makes it available in the form of structured data.
Natural Language Processing
Contextual AI
kinisto recognizes the relationship of text elements to each other and thereby reads information from any type of text, regardless of structure and format. kinisto is fast, high-performance, efficient and, above all, precise.
Natural language is first “clustered” into individual components and the meaning of the text elements as well as their position is detected. Subsequently, kinisto puts all captured text elements in context to each other - both linguistically and with respect to their position in the document. Thus, even complex content relationships can be captured in a wide variety of layouts, formats and formulations.
kinisto reads texts and documents like a human - only faster and more precise.

High-performance Model Training
Data-Centric Active Learning
Get to a kinisto data extraction model efficiently: With kinisto Studio, our own state-of-the-art NLP development environment for data scientists, we train high-performance models for contextual text and document analysis. kinisto Studio’s innovative active learning technology, combined with the ability to optimize raw data, annotation and model in short iteration cycles, enables training in record time.
Training data is the biggest lever for performance. Our data-centric active learning technology optimizes training data for kinisto. kinisto selects the best training data itself and also generates new training data based on existing examples for maximum variance. In the integrated development environment for data scientists, raw data, annotation and model are optimized in short iteration cycles.
This reduces the training time for new use cases by up to 80% and up to 98% less training data is required. kinisto can thus also be trained even for use cases with sensitive data where no real training data is available.
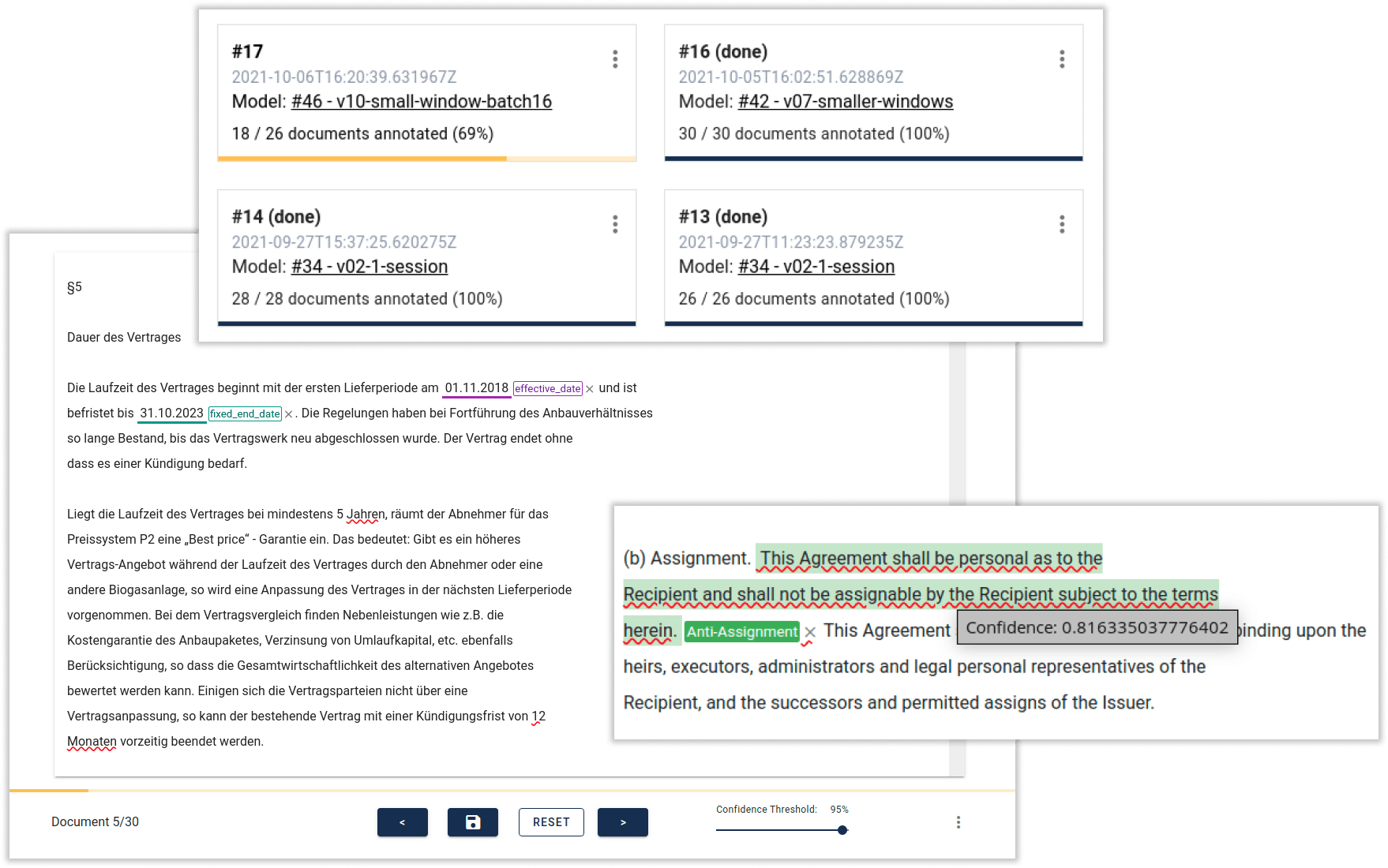
This means that kinisto is ready for your specific use case in the shortest possible time - from the first proof of concept to the deployment of the finished solution. More efficient, better performing, more accurate: automate your document-based processes now with innovative AI technology.
