Classical NLP vs. Deep Learning

This article is an excerpt from the whitepaper Functionality and areas of operation of Natural Language Processing. Read the full whitepaper here.
–
Nothing works without data. There are ready-made NLP solutions that are trained with synthetic data. “Training” in this context means that they make assumptions, test them, analyse them and then optimise themselves accordingly, make new refined assumptions, cast them in new models, test and analyse them again - a continuous and ongoing process. In order to adapt individual NLP solutions to the respective requirements in order to achieve defined goals, they have to be created, ideally with one’s own data.
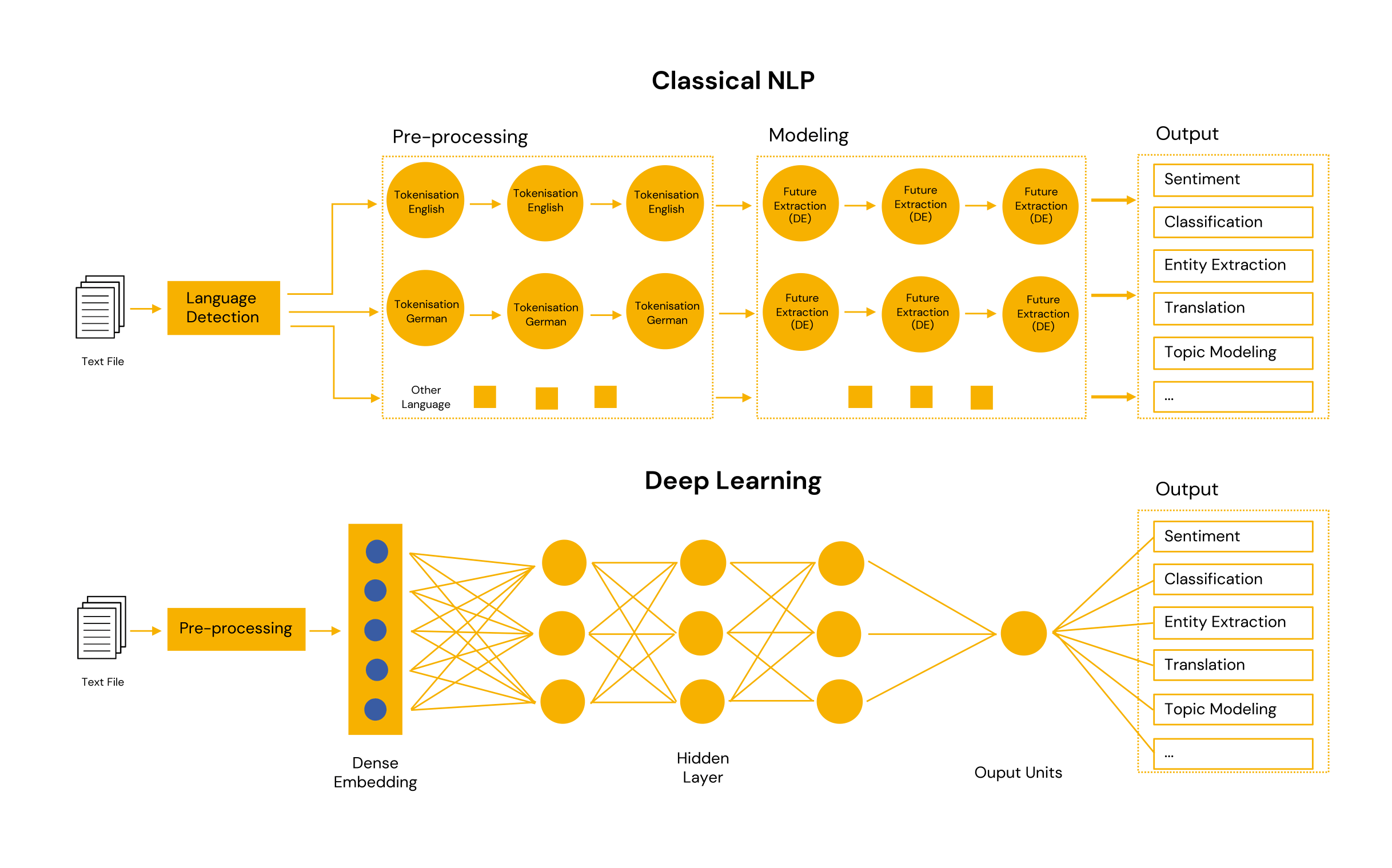
Generalised, one can say that it is about clustering NLP language into individual components. Then to elicit the relationships of these components to each other and to create a context from this.
In syntactic analysis, the arrangement of words in a sentence is examined to see if it makes sense. The syntactic analysis evaluates whether the extracted language conforms to grammatical rules and derives rules from this to create appropriate algorithms. Syntax analysis can be divided into, among others:
- Lemmatisation - a kind of reduction or grouping of different almost meaningless words into groups. For example, “joy”, “enthusiasm”, “cheerfulness” and “pleasure”.
- Word segmentation - the division of a long text document into individual units.
- Stemming - recognising a word in an inflected form and classifying it accordingly.
- Tagging - word types are recognised, i.e. whether verb, noun or adjective etc.
Semantic analysis illuminates the exact content and meaning of a text and places it in context. For this purpose, the example of the German word “bank” - bank for withdrawing money or bank for resting. In addition, semantic analysis forms the basis for the creation of AI-generated texts and voice output - be it short news articles in print or online or the voice assistance systems already mentioned: “Alexa, play me my favourite playlist from last month!
Modern Transformer models perform these steps automatically, so to speak; they are integrated into the developed model. The advantage of this is that you don’t have to do it manually. The disadvantage, however, is that it requires a complex model with a lot of training data to learn all this once.
The AI system for intelligent document processing
Completely integrated into your work process, the AI software kinisto can support employees - previously manual work steps on the document are automatically done by the AI. As a specialist for AI technology in practical use, we will be happy to advise you on the topic and on your specific case!
